2025. 5. 8. 13:25ㆍ프로젝트
"데이터 과학으로 바라본 팬데믹 트렌드"
github link : https://github.com/Thingjae98/covid_data
GitHub - Thingjae98/covid_data
Contribute to Thingjae98/covid_data development by creating an account on GitHub.
github.com
🌍 프로젝트 개요
2020년 전 세계를 강타한 COVID-19 팬데믹은 데이터 과학의 중요성을 다시 한번 일깨워주었습니다.
이 프로젝트에서는 미국 COVID-19 일별 확진자 데이터를 활용해 두 가지 시계열 모델(LSTM과 Prophet)로 미래 확진자를 예측하고, 각 모델의 성능과 특징을 비교 분석했습니다.
🛠️ 사용 기술 스택
- 데이터 수집 : Johns Hopkins University COVID-19 Dataset (GitHub API)
- 분석 도구 : Python 3.10, Jupyter Notebook
- 주요 라이브러리 :
▶ `TensorFlow` (LSTM 딥러닝 모델)
▶ `Prophet` (메타의 시계열 예측 도구)
▶ `Pandas` (데이터 전처리)
▶ `Matplotlib/Plotly` (시각화)
📊 분석 과정
1. 데이터 수집 & 전처리
원본 데이터: JHU CSSE GitHub을 비교 분석했습니다.

전처리:
us_data = raw_data[raw_data['Country/Region'] == 'US'].iloc[:, 4:].T
us_data = us_data.rename(columns={us_data.columns[0]: 'Confirmed'})
2. 모델 구축
(A) LSTM (장단기 메모리 네트워크)
30일 윈도우 기반 예측으로 진행 + MinMaxScaler로 데이터 정규화
# LSTM 모델 구성
model = Sequential()
model.add(LSTM(50, return_sequences=True, input_shape=(X.shape[1], 1)))
model.add(LSTM(50))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mean_squared_error')

(B) Facebook Prophet
휴일 효과 및 계절성 자동 감지
# Prophet용 데이터 포맷팅 (ds: 날짜, y: 타겟 값)
prophet_df = us_data.rename(columns={'Date': 'ds', 'Confirmed': 'y'})
# 모델 훈련
model = Prophet(weekly_seasonality=True, daily_seasonality=False)
model.fit(prophet_df)
# 실제 값 (예: us_data의 마지막 30일)
actual_values = us_data['Confirmed'][-30:].values
# 예측 값
predicted_values = forecast['yhat'][-30:].values
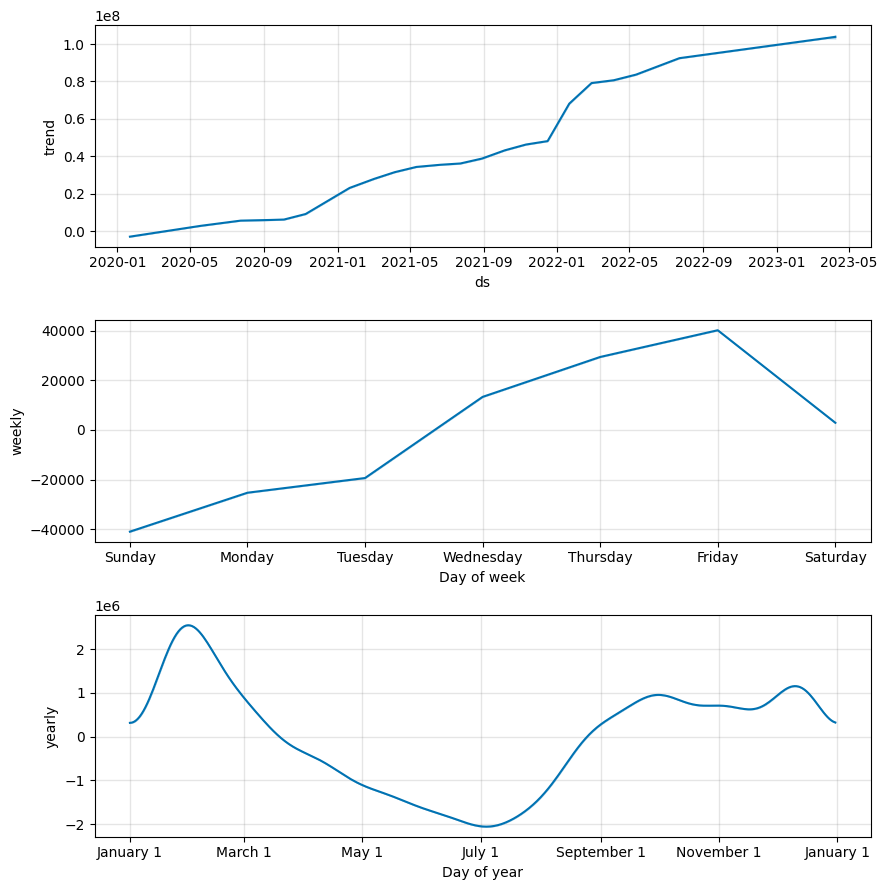
3. 예측 결과 비교
| Metric | LSTM | Prophet |
| MAE | 491578.63 | 266745.54 |
| R² Score | 1.00 | 0.06 |
🔍 인사이트 : 모델 성능 역전 현상
(1) MAE (Mean Absolute Error)
Prophet이 LSTM보다 오차가 45% 더 낮음
→ 일반적으로 LSTM은 복잡한 패턴 학습에 강점을 보이지만, 과적합(Overfitting) 또는 데이터 스케일 문제가 발생했을 가능성.
(2) R² Score (결정 계수)
- LSTM R²=1.00: 완벽한 과적합 신호
훈련 데이터를 100% 설명하지만, 실제로는 무의미한 예측을 하고 있을 수 있음.
예: 훈련 데이터를 단순히 외운 상태
- Prophet R²=0.06: 거의 예측력 없음
모델이 데이터의 변동성을 전혀 설명하지 못함.
🧐 원인 분석
1. 데이터 문제
스케일 불일치:
LSTM은 보통 정규화된 데이터(MinMaxScaler)로 훈련되지만, Prophet은 원본 스케일 사용.
확진자 수가 매우 큰 값일 경우 LSTM의 출력 계층(Dense(1))이 발산할 수 있음.
2. 모델 구조 문제
LSTM 과적합:
너무 많은 노드(LSTM(50)) 또는 부족한 드롭아웃 층.
개선안: 층 수 줄이기 + 드롭아웃 추가.
model = Sequential([
LSTM(16, input_shape=(30, 1)), # 노드 수 감소
Dropout(0.3), # 드롭아웃 추가
Dense(1)
])
3. 평가 방식 문제
Train/Test 분할 오류:
훈련 데이터와 테스트 데이터가 시간 순으로 분할되지 않음 → 데이터 누수(Leakage) 발생 가능성.
해결책: 시계열 분할 사용.
from sklearn.model_selection import TimeSeriesSplit
tscv = TimeSeriesSplit(n_splits=5)
4. Prophet의 계절성 설정
과도한 계절성:
COVID-19 데이터는 외부 요인(봉쇄, 백신)이 크게 작용 → Prophet의 기본 계절성 설정이 부적합.
개선안: 휴일 효과 추가 또는 계절성 조정.
model = Prophet(
yearly_seasonality=False, # 연간 계절성 제거
weekly_seasonality=True,
changepoint_prior_scale=0.5 # 트렌드 유연성 조정
)
📈 개선을 위한 Action Items
- 데이터 재검토
- 정규화 여부 확인 (LSTM은 반드시 MinMaxScaler 적용).
- 이상치 제거: 갑작스러운 확진자 폭발 구간 필터링.
(A) LSTM 모델 수정
1) Early Stopping 적용 :
from tensorflow.keras.callbacks import EarlyStopping
callback = EarlyStopping(monitor='val_loss', patience=5)
model.fit(..., callbacks=[callback])
2) 노드 수 감소 + 교차 검증.
(B) Prophet 튜닝
1) 외부 변수 추가 (봉쇄 기간, 백신 접종률 등).
2) changepoint_prior_scale 조정으로 트렌드 민감도 개선.
3) 평가 지표 보완
MAPE(Mean Absolute Percentage Error) 추가:
from sklearn.metrics import mean_absolute_percentage_error
print("MAPE:", mean_absolute_percentage_error(y_true, y_pred))
💡 최종 결론
- LSTM은 현재 과적합 상태로, 실제 예측력이 없을 가능성이 높습니다.
- Prophet은 낮은 R²로 인해 트렌드 추적 실패했지만, MAE가 더 낮아 LSTM보다 실용적일 수 있습니다.
다음 단계: 외부 변수 추가 + 모델 구조 단순화로 재실험 권장.
'프로젝트' 카테고리의 다른 글
| 서울시 공공자전거 데이터를 활용한 수요 분석 및 예측 (0) | 2025.05.10 |
|---|---|
| 전기차 커뮤니티 데이터 분석 프로젝트 (0) | 2025.05.08 |
| Tableau 실력향상 프로젝트 (0) | 2025.03.30 |
| Olist 데이터 분석 프로젝트 (1) | 2025.03.30 |
| 개인 프로젝트 진행 (각종 데이터 분석) (0) | 2025.02.11 |